


2018 was the second consecutive year when Gartner published an obituary of Big Data. If this sounds like bad news, don’t panic! No one, including Gartner, thinks Big Data is dead. Au contraire, Big Data has grown so ubiquitous it became “just data”, or so argue the authors of the obituaries.
Data certainly was all over the place in 2018 so let’s see how the market has changed and what to expect in 2019 and beyond. This article covers 4 trends that will shape the data technology in the next few years.
Trend 1: From Big Data to “Just Data”
Looking back at the technology landscape of 2016–2018, the buzz surrounding Big Data has been on the decline:
At the same time, thousands of companies have been embracing data. Forbes and Dresner report that enterprise adoption of Big Data reached 58% in 2018, a significant increase from 2015’s modest, but respectable, 17%.
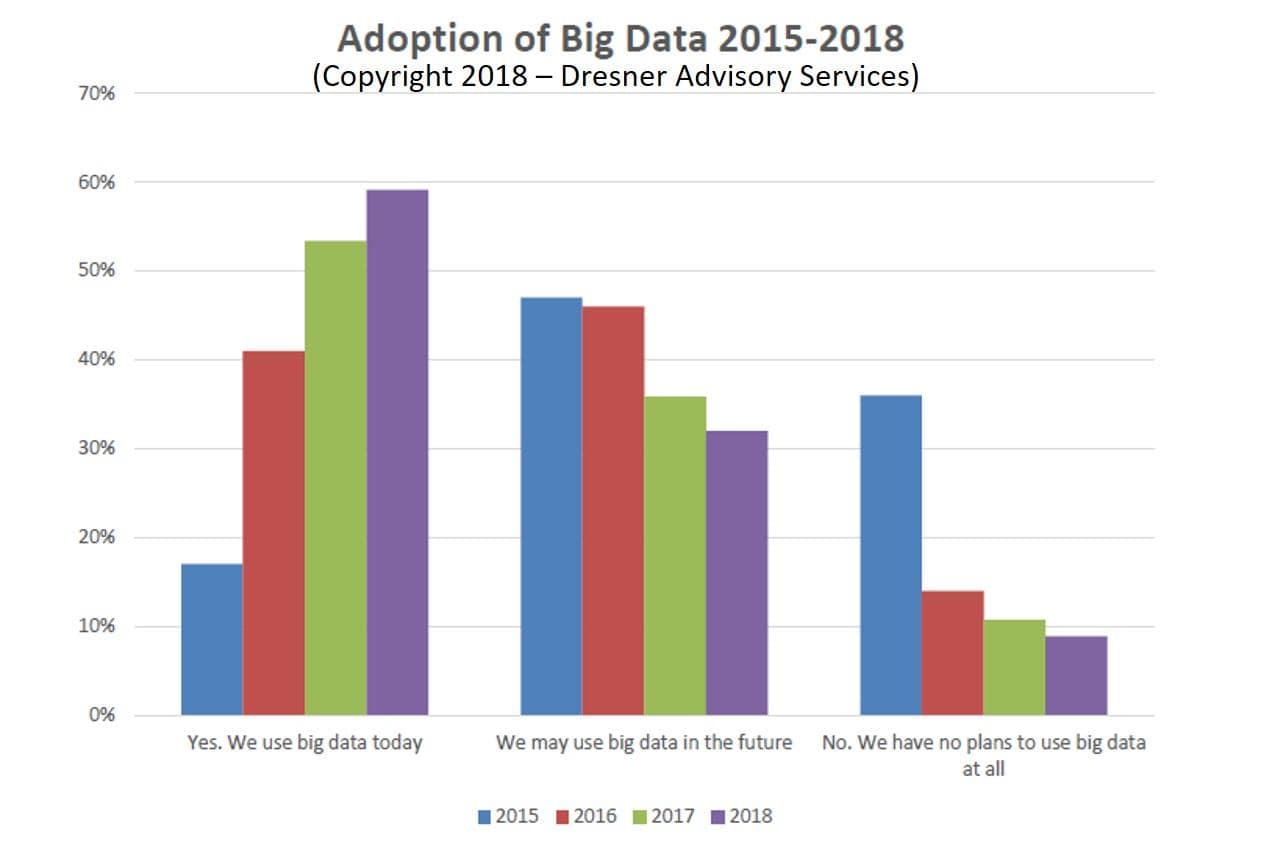
Source: Dresner (via Forbes)
Data has reached the late majority of adopters in the 2017–2018 period, a trend that persists in 2019. The public no longer views data as a new exciting frontier — rather, a technology that companies must adopt to stay competitive. Big Data is now less of a buzzword, yet it’s now an integral component in the ongoing digital transformation of enterprises.
Trend 2: Machine Learning is the New Black
Now that Big Data is officially a boring technology, machine learning became another buzzword hitting the spotlight. In August 2018, deep learning reached the peak of Gartner’s Hype Cycle for Emerging Technologies. Machine learning–enabled data management also entered the pre-peak section of Gartner’s Hype Cycle for Data Management.
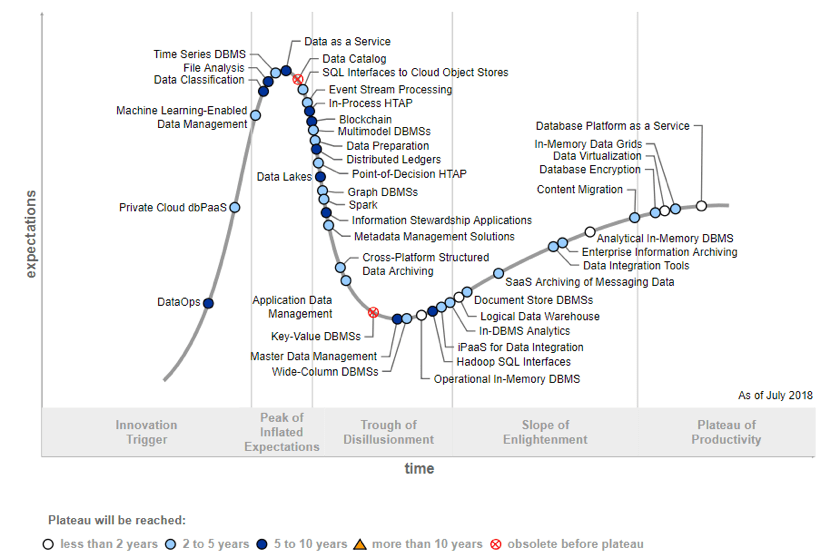
Source: Hype Cycle for Data Management, 2018
This perfectly illustrates the general craze about machine learning — and explains why large data companies are also AI/ML companies.
As Dieter Bohn from the Verge pointed out, nowadays, Google can’t string five words together without mentioning AI
. And it’s not just the search giant, either. Google Cloud, Microsoft Azure, and AWS are some of the biggest brands in machine learning as a service (MLaaS). Coincidentally, these three companies are also among the leaders in modern Big Data infrastructures:
| Google Cloud | AWS | Microsoft Azure | |
|---|---|---|---|
| Cloud EDW (Data Warehouse) | Google BigQuery | Amazon Redshift | SQL Server Data Warehousing |
| Data Storage | Google Cloud Storage | Amazon S3 | Azure Blob Storage |
| Hadoop in the Cloud | Cloud Dataproc | Amazon Elastic Map Reduce | Microsoft Azure HDInsight |
| Stream analytics | Cloud DataFlow | Amazon Kinesis | Azure Stream Analytics |
| Cluster services | Borg, Kubernetes, Omega | Elastic Container Service (Amazon ECS) | Azure Kubernetes Service (AKS) |
| Analytics / BI platforms | Google Cloud BI solution | Amazon QuickSight | Microsoft Power BI |
| ML as a Service | Cloud AI | Amazon ML | Azure Machine Learning service |
Here’s another indicator of the skyrocketing prominence of AI and ML in the data scene. What has been Matt Turck’s Big Data Landscape in 2017 became the Big Data and AI Landscape in 2018:

Source: Big Data and AI Landscape in 2018 (Click to view the full version).
Trend 3: Everyone, to the Cloud!
The domination of AWS, Google Cloud, and Microsoft Azure in the data market marks another important trend. An increasing number of the modern-day adopters of Big Data show little interest in developing and provisioning on-premise Hadoop or Spark infrastructures. Instead, they chose to rely on the simplicity of fully-managed, serverless solutions on the cloud. And they have quite a few reasons to do so:
- Low entrance threshold. With cloud, there’s no need to order and wait for server equipment, rent server rooms, license software, or set up the infrastructure. As a result, the adoption of Big Data on the cloud feels like less of a commitment.
- Simple scalability. Services like Amazon S3 offer readymade infrastructures that easily scale past tens of trillions of objects. Scaling an on-premise infrastructure, on the other hand, requires new equipment, new architecture/code, and new effort.
- Cost: 1TB of cloud object storage can cost as little as $20 per month, which compares favorably to what companies pay for in-house HDFS infrastructures.
- The flexibility of FaaS. Handling distributed queries on an ad-hoc basis is the default use case for Spark. BigQuery offers exactly the same functionality, and you only pay for what you use, when you use it.
- Language barrier. The advent of data science in the enterprise segment raises the need to write and iterate ML models in Python and R. On-premise Hadoop and Spark setups, on the other hand, natively favor Java and Scala.
Practical reasoning aside, the growing popularity of cloud platforms is perfectly in line with the psychology of the Product Adoption Curve.
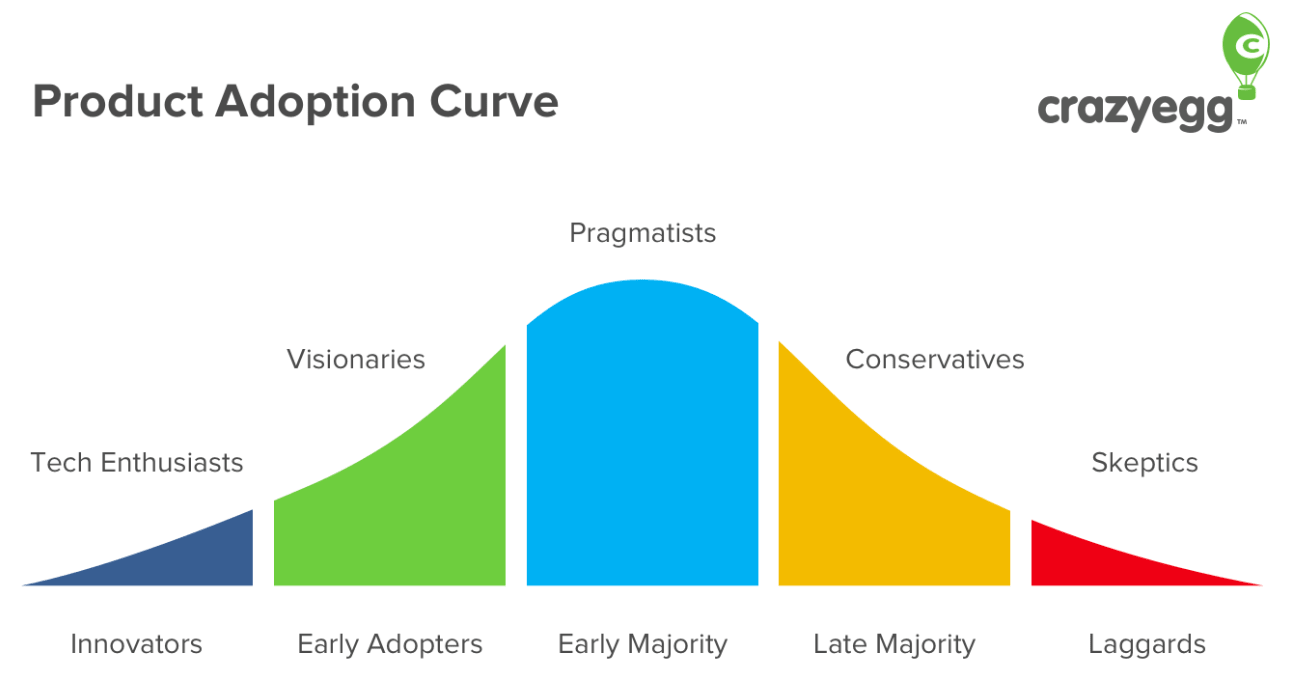
Source: CrazyEgg
If you think about it, it’s been 13 years since Hadoop emerged and Big Data became a thing. People adopting this technology today are the late majority, and the late majority wants pre-assembled, value-added, and reasonably-priced solutions. That’s exactly how Amazon, Google, and Microsoft market AWS, Google Cloud, and Azure.
Trend 4: Zero Tolerance for Data Mismanagement
In 2019, data governance strategies might need a stronger focus on data security. There had been quite a few prerequisites for this last year:
- In February 2018, the breach of the MyFitnessPal app exposed the data of 150 million users.
- March 2018 saw the news of Cambridge Analytica’s misappropriation of the personal information of 87 million Facebook users. Later investigations revealed broader issues with data mismanagement at Facebook.
- In July, the breach of the Polar fitness app compromised the location data of the US military and security personnel.
- In August and September, a hacker group named Magecart had been hijacking the payments data of 50 million online shoppers via the Newegg platform.
- In November, a security vulnerability of ElasticSearch exposed the data of 82 million users (57 million people and 26 million companies).
- In December, the names, email addresses, and passwords of 100 million Quora users leaked to a third party.
These are just of few high-profile examples that made headlines last year. The good news is that the privacy issues of 2018 faced public and political resonance. Facebook’s Mark Zuckerberg had to testify before the US Congress, and the EU adopted the GDPR, a regulation aimed to protect user privacy. In early February of 2019, Cisco and Apple urged the US government to adopt similar regulations.
The side effect of these events is greater public scrutiny of how companies handle and protect user data. Naturally, this implies an opportunity for startups ready to offer solutions for data governance and data security. There will be other opportunities for startups and enterprises in the data space as well.
Opportunities in the data space in 2019
As adoption of data continues, startups will need to differentiate themselves to conquer a niche in the still booming market. According to the investor Matt Turk, the niches that offer space for growth in 2019 are:
- Data governance and security
- Solutions for real-time streaming and processing of Big Data
- Data fabrics
- Data visualization
- GPU databases
- AI (including AI devops solutions)
- Solutions that enable and streamline the deployment of data science and machine learning solutions for enterprises.
Speaking of enterprises, InsideBigData names several opportunities for efficiency gains in 2019 and beyond:
- According to InsideBigData, up to 80% of all collected data remains cold/unused. Finding solutions for utilizing this data would be game-changing.
- The maximum cluster utilization across the tech industry is 70%% while the average is 45%. Both figures indicate a huge potential for optimization.
- Firefighting issues take up to 70% of time spent by professionals involved in Big Data. The factors leading to this statistic involve skills shortage, systems/tools complexity and inadequacy.
Whether you are a data startup, or an enterprise looking to optimize efficiency, finding the right talent is paramount. The good news is that we specialize in helping companies reach talented software developers. Our engineers have worked on numerous products building and streamlining Big Data solutions or helping enterprises integrate with AWS, Google Cloud, and Azure.
If you are looking for someone who’s right for the job, contact us and ask our guys about our expertise with Big Data.




